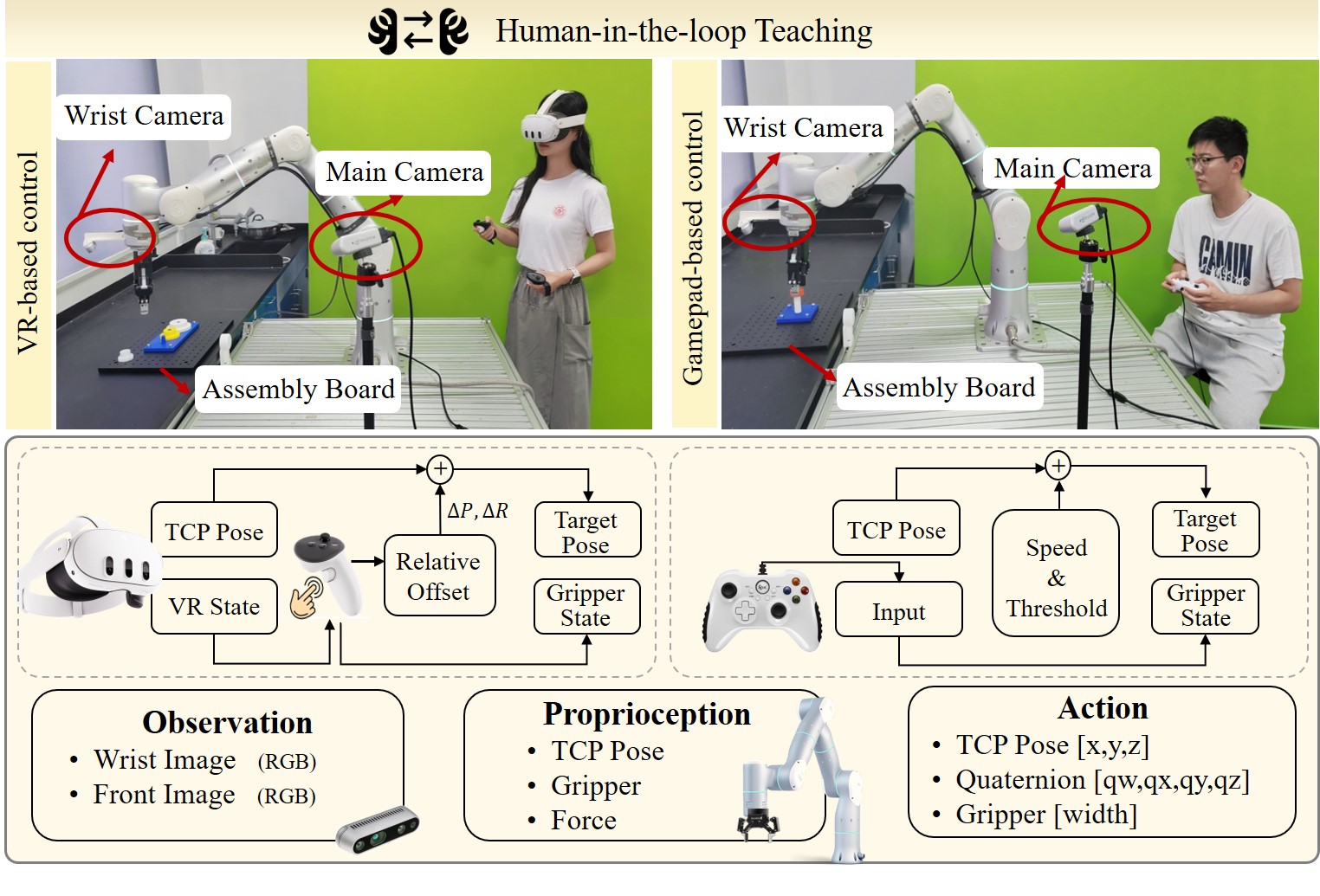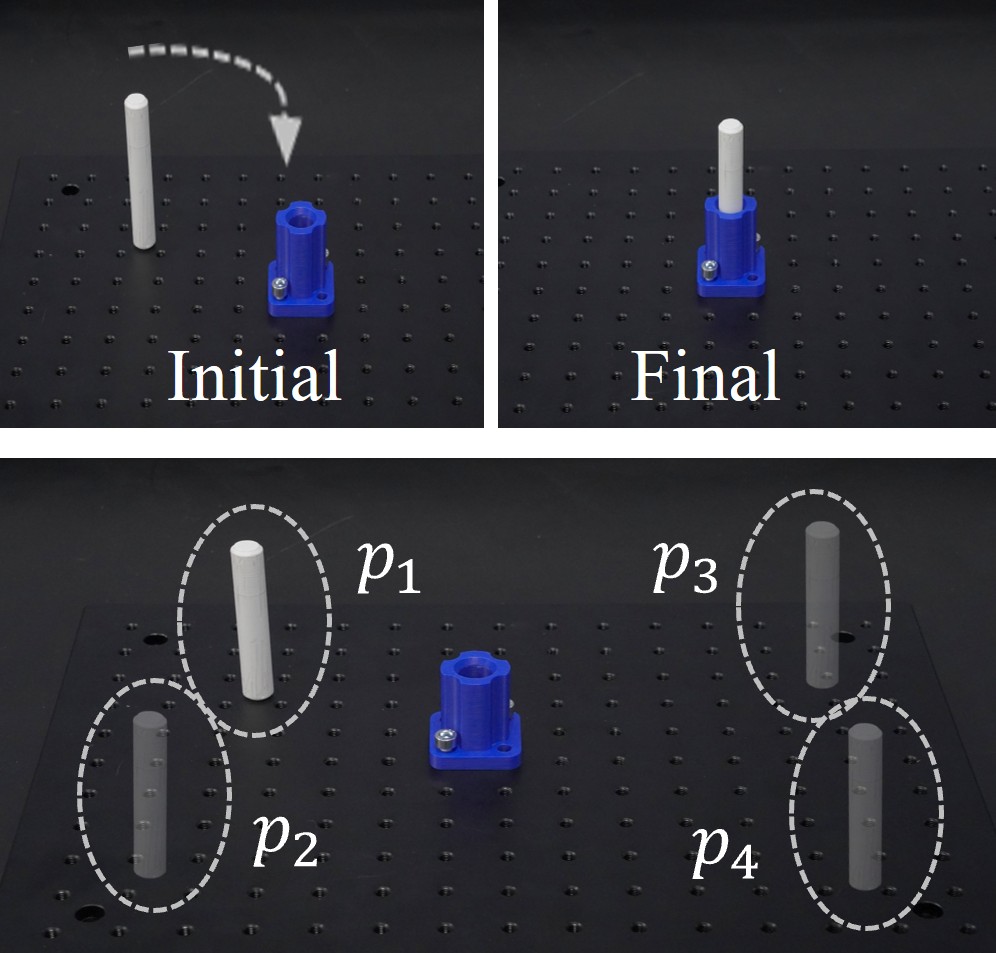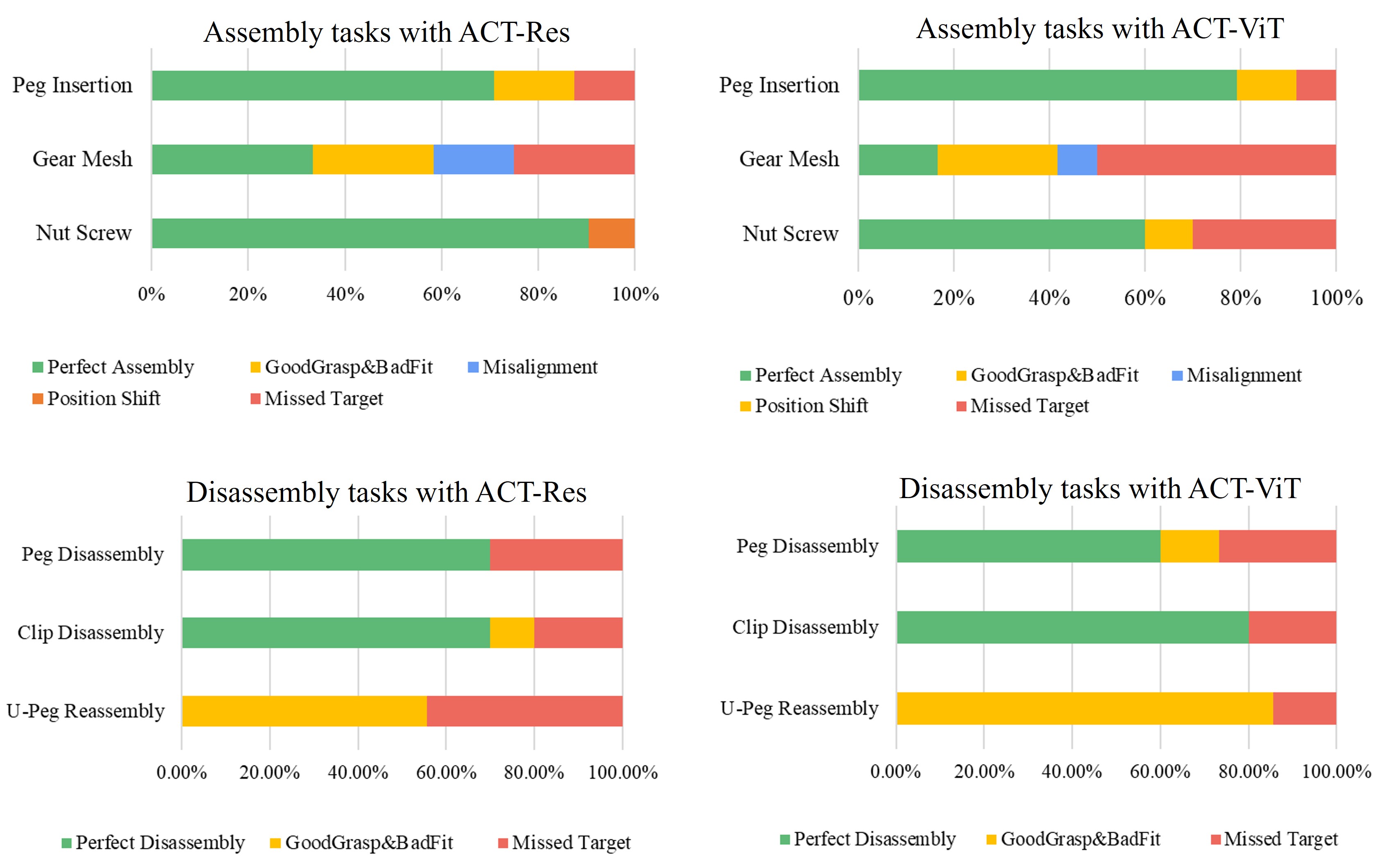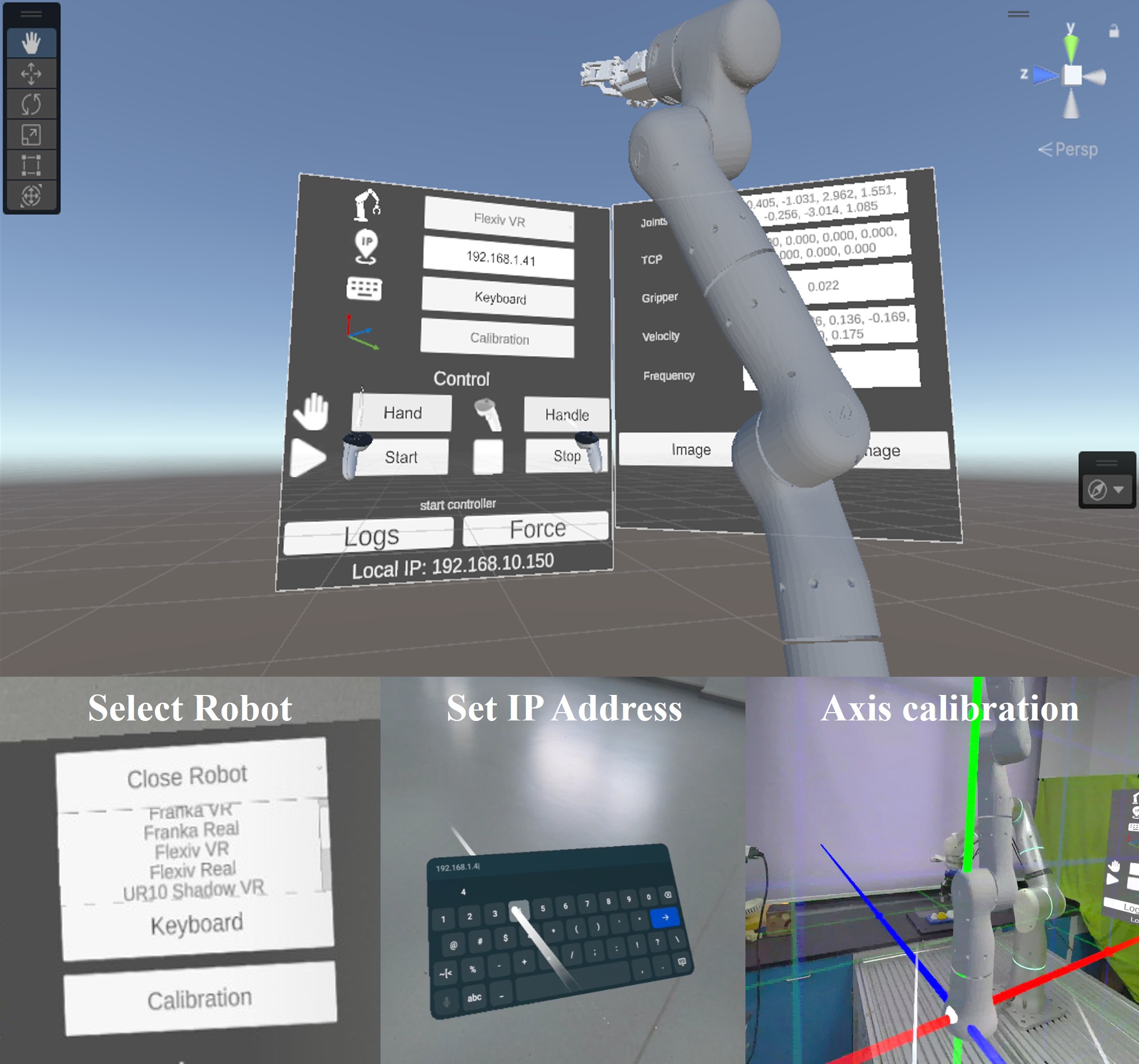
Human Demonstration Collection
This work implements two complementary teleoperation modes for demonstration collection: 1) VR-based position control and 2) gamepad-based velocity control. The VR control enables precise 6-DoF trajectory demonstrations via spatial mapping, while gamepad-based velocity control ensures stable, millimeter-scale screw-fastening through fine-grained force adjustment.